前言
有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到的问题以及处理经验和优化建议,包括以下方面的内容:
- 有赞数据平台的整体架构。
- SparkSQL 在有赞的技术演进。
- 从 Hive 到 SparkSQL 的迁移之路。
一. 有赞数据平台介绍
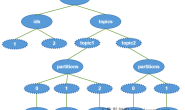
首先介绍一下有赞大数据平台总体架构:
如下图所示,底层是数据导入部分,其中 DataY 区别于开源届的全量导入导出工具 alibaba/DataX,是有赞内部研发的离线 Mysql 增量导入 Hive 的工具,把 Hive 中历史数据和当天增量部分做合并。DataX / DataY 负责将 Mysql 中的数据同步到数仓当中,Flume 作为日志数据的主要通道,同时也是 Mysql binlog 同步到 HDFS 的管道,供 DataY 做增量合并使用。
第二层是大数据的计算框架,主要分成两部分:分布式存储计算和实时计算,实时框架目前主要支持 JStorm,Spark Streaming 和 Flink,其中 Flink 是今年开始支持的;而分布式存储和计算框架这边,底层是 Hadoop 和 Hbase,ETL主要使用 Hive 和 Spark,交互查询则会使用 Spark,Presto,实时 OLAP 系统今年引入了 Druid,提供日志的聚合查询能力。
第三层是数据平台部分,数据平台是直接面对数据开发者的,包括几部分的功能,数据开发平台,包括日常使用的调度,数据传输,数据质量系统;数据查询平台,包括ad-hoc查询以及元数据查询。有关有赞数据平台的详细介绍可以参考往期有赞数据平台的博客内容。

二. SparkSQL技术演进
从2017年二季度,有赞数据组的同学们开始了 SparkSQL 方面的尝试,主要的出发点是当时集群资源是瓶颈,Hive 跑任务已经逐渐开始乏力,有些复杂的 SQL,通过 SQL 的逻辑优化达到极限,仍然需要几个小时的时间。业务数据量正在不断增大,这些任务会影响业务对外服务的承诺。同时,随着 Spark 以及其社区的不断发展,Spark 及 Spark SQL 本身技术的不断成熟,Spark 在技术架构和性能上都展示出 Hive 无法比拟的优势。
从开始上线提供离线任务服务,再到 Hive 任务逐渐往 SparkSQL 迁移,踩过不少坑,也填了不少坑,这里主要分两个方面介绍,一方面是我们对 SparkSQL 可用性方面的改造以及优化,另一方面是 Hive 迁移时遇到的种种问题以及对策。
2.1 可用性改造
可用性问题包括两方面,一个是系统的稳定性,监控/审计/权限等,另一个是用户使用的体验,用户以前习惯用 Hive,如果 SparkSQL 的日志或者 Spark thrift server 的 UI 不能够帮助用户定位问题,解决问题,那也会影响用户的使用或者迁移意愿。所以我首先谈一下用户交互的问题。
用户体验
我们碰到的第一个问题是用户向我们抱怨通过 JDBC 的方式和 Spark thrift server(STS) 交互,执行一个 SQL 时,没有执行的进度信息,需要一直等待执行成功,或者任务出错时接收任务报错邮件得知执行完。于是执行进度让用户可感知是一个必要的功能。我们做了 Spark 的改造,增加运行时的 operation 日志,并且向社区提交了 patch(spark-22496), 而在我们内部,更增加了执行进度日志,每隔2秒打印出当前执行的 job/stage 的进度,如下图所示。

监控
SparkSQL 需要收集 STS 上执行的 SQL 的审计信息,包括提交者执行的具体 SQL,开始结束时间,执行完成状态。原生 STS 会把这些信息通过事件的方式 post 到事件总线,监听者角色 (HiveThriftServer2Listener) 在事件总线上注册,订阅消费事件,但是这个监听者只负责 Spark UI 的 JDBC Tab 上的展示,我们改造了 SparkListener 类,将 session 以及执行的 sql statement 级别的消息也放到了总线上,监听者可以在总线上注册,以便消费这些审计信息,并且增加了一些我们感兴趣的维度,如使用的 cpu 资源,归属的工作流(airflowId)。同时,我们增加了一种新的完成状态 cancelled,以方便区分是用户主动取消的任务。

Thrift Server HA
相比于 HiveServer,STS 是比较脆弱的,一是由于 Spark 的 driver 是比较重的,所有的作业都会通过 driver 编译 sql,调度 job/task 执行,分发 broadcast 变量,二是对于每个 SQL,相比于 HiveServer 会新起一个进程去处理这个 SQL 的执行,STS 只有一个进程去处理,如果某个 SQL 有异常,查询了过多的数据量, STS 有 OOM 退出的风险,那么生产环境维持 STS 的稳定性就显得无比重要。
除了必要的存活报警,首先我们区分了 ad-hoc 查询和离线调度的 STS 服务,因为离线调度的任务往往计算结束时是把结果写入 table 的,而 ad-hoc 大部分是直接把结果汇总在 driver,对 driver 的压力比较大;此外,我们增加了基于 ZK 的高可用。对于一种类型的 STS(事实上,有赞的 STS 分为多组,如 ad-hoc,大内存配置组)在 ZK 上注册一个节点,JDBC 的连接直接访问 ZK 获取随机可用的 STS 地址。这样,偶然的 OOM ,或者 bug 被触发导致 STS 不可用,也不会严重到影响调度任务完全不可用,给开发运维人员比较充足的时间定位问题。
权限控制
之后有另一个文章详细介绍我们对于安全和权限的建设之路,这里简单介绍一下,Hive的权限控制主要包括以下几种:
- SQL Standards Based Hive Authorization
- Storage Based Authorization in the Metastore
- ServerAuthorization using Apache Ranger & Sentry
调研对比各种实现方案之后,由于我们是从无到有的增加了权限控制,没有历史负担。我们直接选择了ranger + 组件 plugin 的权限管理方案。
除了以上提到的几个点,我们还从社区 backport 了数十个 patch 以解决影响可用性的问题,如不识别 hiveconf/hivevar (SPARK-13983),最后一行被截断(HIVE-10541) 等等。
2.2 性能优化
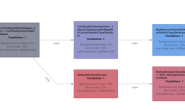
之前谈到,STS 只有一个进程去处理所有提交 SQL 的编译,所有的 SQL Job 共享一个 Hive 实例,更糟糕的是这个 Hive 实例还有处理 loadTable/loadPartition 这样的 IO 操作,会阻塞其他任务的编译,存在单点问题。我们之前测试一个上万 partition 的 Hive 表在执行 loadTable 操作时,会阻塞其他任务提交,时间长达小时级别。对于 loadTable 这样的IO操作,要么不加锁,要么减少加锁的时间。我们选择的是后者,首先采用的是社区 SPARK-20187 的做法,将 loadTable 实现由 copyFile 的方式改为 moveFile,见下图:

之后变更了配置spark.sql.hive.metastore.jars=maven,运行时通过 Maven 的方式加载 jar 包,解决包依赖关系,使得加载的 Hive 类是2.1.1的版本,和我们 Hive 版本一致,这样得好处是很多行为都会和 Hive 的相一致,方便排查问题;比如删除文件到 Trash,之前 SparkSQL 删除表或者分区后是不会落到 Trash 的。
2.3 小文件问题
我们在使用 SparkSQL 过程中,发现小文件的问题比较严重,SparkSQL 在写数据时会产生很多小文件,会对 namenode 产生很大的压力,进而带来整个系统稳定性的隐患,最近三个月文件个数几乎翻了个倍。对于小文件问题,我们采用了社区 SPARK-24940 的方式处理,借助 SQL hint 的方式合并小文件。同时,我们有一个专门做 merge 的任务,定时异步的对天级别的分区扫描并做小文件合并。
还有一点是spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=2, MapReduce-4815 详细介绍了 fileoutputcommitter 的原理,实践中设置了 version=2 的比默认 version=1 的减少了70%以上的 commit 时间。
三. SparkSQL 迁移之路
解决了大部分的可用性问题以后,我们逐步开始了 SparkSQL 的推广,引导用户选择 SparkSQL 引擎,绝大部分的任务的性能能得到较大的提升。于是我们进一步开始将原来 Hive 执行的任务向 SparkSQL 转移。
在 SparkSQL 迁移之初,我们选择的路线是遵循二八法则,从优化耗费资源最多的头部任务开始,把Top100的任务从 Hive 往 SparkSQL 迁移,逐步积累典型错误,包括 SparkSQL 和Hive的不一致行为,比较典型的问题由ORC格式文件为空,Spark会抛空指针异常而失败,ORC 格式和 metastore 类型不一致,SparkSQL 也会报错失败。经过一波人工推广之后,头部任务节省的资源相当客观,在2017年底,切换到 SparkSQL 的任务数占比5%,占的资源20%,资源使用仅占 Hive 运行的10%-30%。
在 case by case 处理了一段时间以后,我们发现这种方式不太能够扩展了。首先和作业的 owner 协商修改需要沟通成本,而且小作业的改动收益不是那么大,作业的 owner 做这样的改动对他来说收益比较小,反而有一定概率的风险。所以到这个阶段 SparkSQL 的迁移之路进展比较缓慢。
于是我们开始构思自动化迁移方式,构思了一种执行引擎之上的智能执行引擎选择服务 SQL Engine Proposer(proposer),可以根据查询的特征以及当前集群中的队列状态为 SQL 查询选择合适的执行引擎。数据平台向某个执行引擎提交查询之前,会先访问智能执行引擎选择服务。在选定合适的执行引擎之后,数据平台将任务提交到对应的引擎,包括 Hive,SparkSQL,以及较大内存配置的 SparkSQL。

并且在 SQL Engine Proposer,我们添加了一系列策略:
- 规则策略,这些规则可以是某一种 SQL pattern,proposer 使用 Antlr4 来处理执行引擎的语法,对于某些迁移有问题的问题,将这种 pattern 识别出来,添加到规则集合中,典型的规则有没有发生 shuffle 的任务,或者只发生 broadcast join 的任务,这些任务有可能会产生很多小文件,并且逻辑一般比较简单,使用Hive运行资源消耗不会太多。
- 白名单策略,有些任务希望就是用Hive执行,就通过白名单过滤。当 Hive 和 SparkSQL 行为不一致的时候,也可以先加入这个集合中,保持执行和问题定位能够同时进行。
- 优先级策略,在灰度迁移的时候,是从低优先级任务开始的,在 proposer 中我们配置了灰度的策略,从低优先级任务切一定的流量开始迁移,逐步放开,在优先级内达到全量,目前放开了除 P1P2 以外的3级任务。
- 过往执行记录,proposer 选择时会根据历史执行成功情况以及执行时间,如果 SparkSQL 效率比 Hive 有显著提升,并且在过去一直执行成功,那么 proposer 会更倾向于选择 SparkSQL。
截止目前,执行引擎选择的作业数中 SparkSQL 占比达到了73%,使用资源仅占32%,迁移到 SparkSQL 运行的作业带来了67%资源的节省。


未来展望
我们计划 Hadoop 集群资源进一步向 SparkSQL 方向转移,达到80%,作业数达70%,把最高优先级也开放到选择引擎,引入 Intel 开源的 Adaptive Execution 功能,优化执行过程中的 shuffle 数目,执行过程中基于代价的 broadcast
join 优化,替换 sort merge join,同时更彻底解决小文件问题。
主要负责有赞的数据平台(DP), 实时计算(Storm, Spark Streaming, Flink),离线计算(HDFS, YARN, HIVE, SPARK SQL),在线存储(HBase),实时 OLAP(Druid) 等数个技术产品